

全国统一销售热线




地址:广东省清远市
电话:0898-08980898
传真:000-000-0000
邮箱:admin@youweb.com
更新时间:2024-07-22 07:46:15
高能预警:本文涉及大量的数学推导,如有不适,概不负责。
在回归问题(regression problems)中,我们常用平方误差和(sum of squares)来衡量模型的好坏。
回归问题可以定义如下:
给定一个包含 个数据的训练集
,以及这些数据对应的目标值
,回归问题的目标是利用这组训练集,寻找一个合适的模型,来预测一个新的数据点
对应的目标值
。记模型的参数为
,模型对应的函数为
,模型的预测值可以相应表示为
。
为了衡量模型的好坏,需要一种方法衡量预测值与目标值之间的误差,一个常用的选择是平方误差和:
平方误差和函数可以看成是每个数据点 的预测值
到真实目标值
的误差平方和的一半。
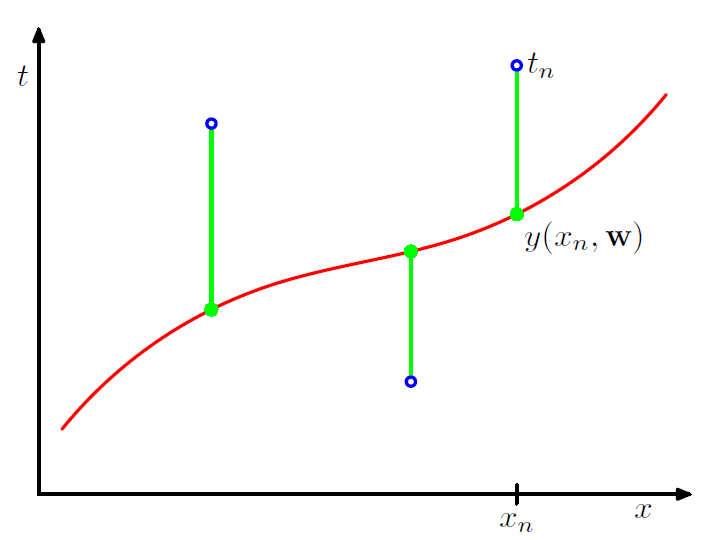
不同的参数 对应于不同的误差函数
,因此,回归问题的目标通常是找到一组参数
使得误差函数
最小化。
那么最小化 究竟有什么意义呢?
在回答这个问题之前,我们需要先复习一下概率知识。
先复习一下与条件概率相关的贝叶斯公式:
对于回归问题来说,如果我们记训练集为 ,那么对于模型参数
来说,贝叶斯公式给出:
其中 表示的是参数
的先验(prior)分布;
给定参数为
的情况下,训练数据为
的可能性,我们也可以把它看成一个关于
的函数,这个函数叫做似然函数(likelihood function);
是参数
在给定数据
下的后验(posterior)分布。
给定这些定义,贝叶斯公式可以表示成:
即后验正比于似然乘以先验。
似然函数是一个非常重要的概念。通过极大似然函数 ,我们可以找到一个最优的参数
,使得在这组参数设定下,出现训练数据
的可能性
最大。这组参数在统计上叫做参数
的极大似然估计。
早在上初中的时候,我们就学到了在做实验时,需要多次测量取平均来减少误差的道理。我们也知道,误差会来自两个部分:系统误差和随机误差。通过多次测量能够减少随机误差,但是不能减少系统误差,所以测量误差是不可避免的。
同样道理,在回归问题中, 的测量值
会存在一定的误差。
假定对所有的数据点 ,模型预测值
与目标值
之间的误差是一样的,并服从一定的概率分布,比如均值为0,方差为
的高斯分布,则有:
即:
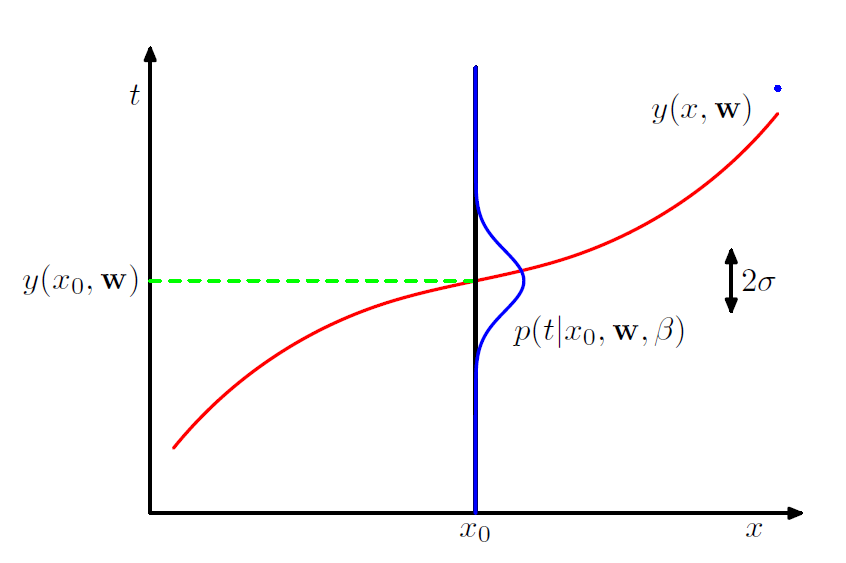
对于一组独立同分布的数据点 ,以及这些数据对应的目标值
,我们得到关于这组数据的似然函数:
其中,高斯分布的概率函数为:
可以通过极大化这个似然函数得到关于 的一组极大似然解。
不过,更方便的做法是极大对数似然函数,因为对数函数是严格单增的,所以极大对数似然的解与极大似然的解是相同的。
对数似然函数为:
如果我们不考虑 的影响,那么,对于参数
来说,最小化平方误差和的解,就等于极大对数似然的估计。
因此,最小化平方误差和 与极大似然等价,考虑到似然函数的定义,优化
相当于在给定高斯误差的假设下,寻找一组
使得观察到目标值t的概率最大。
现在考虑另一类问题——分类问题。
我们同样给出定义:
给定一个包含 个数据样本的训练集
,以及这些数据对应的类别
,这里,
,分类问题的目标是利用这组训练集,寻找一个合适的模型,来预测一个新的数据点
对应的类别
。现在假设模型的参数为
,模型输出是属于每一类的概率,预测为第
类的概率为
。
对于样本 ,其属于第
类的概率为:
其中, 。
因此,似然函数为:
对数似然为:
极大化对数似然,相当于极小化:
事实上,这正是我们常使用的多类交叉熵损失函数的表示形式。
因此,在分类问题中,最小化交叉熵损失函数相当与极大样本的似然函数。
在优化目标函数时,除了正常的损失函数外,为了防止过拟合,我们通常会加入一些正则项,比如权值衰减(weight decay),lasso等等。
比如,在回归问题中,使用权值衰减后,目标函数可能是:
这里,我们假定 可以被拉长表示为一个一维向量。
此时,优化这个目标函数就不能用极大似然来解释了。
不过,如果我们观察贝叶斯公式:
以及:
我们会发现,如果对两边取对数,那么有:
那么,我们加入的正则项,是不是对应于 的先验分布
呢?
答案当然是肯定的。
如果给出参数 的先验,那么极大后验估计(Maximize a Posterior, MAP)是能给出类似带正则项目标函数
的结构的。
问题是什么样的先验会给出类似权值衰减的正则项呢?
一个通常的想法是我们认为参数 服从的先验分布是一个均值0,方差
的D维高斯分布,那么,我们有:
其对数为:
结合我们之前的推导,我们有:
因此,加权值衰减的正则与高斯分布先验下极大后验估计的结果一致。
对于分类问题,该结论依然成立。
我们已经将解释了目标函数中,优化某些损失函数和正则项的意义。在解释更多的损失函数和正则项之前,需要先解决一个问题。
为什么是高斯分布?怎么老是高斯分布?
先给出结论:
对于一个连续随机变量 ,在给定均值和方差的约束下,交叉信息熵最大的分布是高斯分布。
熵是描述系统混乱度的概念,热力学第二定律告诉我们,在没有外力作用时,熵总是趋于自增的,因此,上面的结论告诉我们,生活中很多现象服从高斯分布并不是偶然。
先引出信息熵的概念。
先考虑一个离散随机变量 ,给定一个该随机变量的观察值
,希望用一个函数
去衡量
所携带的信息量。一般来说,如果
是一件概率很低的事情,那么我们会觉得它很有信息量,反之,如果
是一件经常发生的事情,那么我们会觉得信息量很少。因此,信息量会和
发生的概率
相关。
另一方面,我们认为,如果两个事件 和
是相互独立的,那么,我们认为两者携带的信息量是各自信息量之和:
另一方面。独立性给出:
再考虑约束,当 时,
,不难看出,符合条件的是概率密度的对数函数,不妨定义为:
这里,使用2为底的对数并不是必须的,也可以使用其他底。不过使用2为底,信息的单位就变成了bit。
对于一个离散分布 来说,其信息的期望为:
我们把 叫做这个随机变量的熵。
比如说,对于一个等概率,取值为8个的离散分布,其熵为:
3比特正是用2进制表示这8个值所需要的大小。
再比如说,考虑取值为 ,概率为:
的分布,其熵为:
而这正是用霍夫曼编码a:0,b:10,c:110,d:111表示这四个值的平均比特大小。
除了以2为底,我们还可以以其他对数为底,比如自然对数:
连续分布:
现在假设某个分布满足:
在这些假设下,为了使 最大,其Lagrange函数为:
即:
利用变分法中的欧拉-拉格朗日方程
我们得到使得 最大的
需要满足:
即:
带入约束中,不难解出:
即高斯分布是满足约束下,熵最大的分布。
接下来,我们讨论其他的损失函数与正则。
事实上,如果我们考虑更一般的分布:
不难得出:
在回归问题中,如果我们用这个分布作为预测值与目标值之间误差的分布:
那么,对应的损失函数为 损失函数:
如果我们认为参数 的先验服从该分布:
那么,对应的正则项为 正则项:
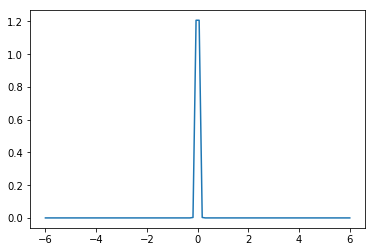
当 时,我们相当于加了一个
范数的正则项,即Lasso,它通常具有稀疏的作用,原因是此时参数的先验分布大概长这个样子:
总而言之,优化损失函数与正则项,其实代表的是对参数 的极大似然或者极大后验估计,不同的损失函数和正则项,反映的我们对参数先验分布和似然函数的不同假设。
[1]Christopher, M. Bishop. "Pattern recognition and machine learning." Company New York 16.4 (2006): 049901.



